摘要
这篇论文总结了在NIPS2016上作者提出的向导。
这个向导主要包括:
- 为什么生成模型值得研究
- 生成模型怎么工作,以及GANs与其他生成模型的比较
- GANs工作的一些细节
- GAN相关的研究课题
- 结合GAN与其他发放的最先进图像模型 最后,这篇向导为读者提供了3个练习,以及练习的答案。
介绍
这个报告总结了在2016NIPS大会上关于GANs的内容。为了确保这个向导对观众最有用,这个向导主要面向去确定在大会初期由观众提出的问题。这个向导不计划全面的介绍GANs的领域;很多出彩的论文没有在这里被提及,只是因为这些论文没有对频繁出现的问题作出解释,另外因为这个向导被设置为2个小时的口述演讲,也没有无限的时间覆盖所有的研究内容。
这个向导将介绍:
- 为什么生成模型是一个值得研究的题目
- 生成模型是如何工作的,以及GAN与其他生成模型的区别
- GANs工作的细节
- GANs的相关研究课题
- 最先进的包含GANs和其他方法的图像模型 最后,这个向导包含3个练习给读者完成,同时提供了这3个练习的答案。
此向导的幻灯片可以查看在PDF和Keynote格式在下面的链接中: http://www.iangoodfellow.com/slides/2016-12-04-NIPS.pdf http://www.iangoodfellow.com/slides/2016-12-04-NIPS.key
视频被NIPS基金会录制,可以在稍后进行观看。 https://channel9.msdn.com/Events/Neural-Information-Processing-Systems-Conference/Neural-Information-Processing-Systems-Conference-NIPS-2016/Generative-Adversarial-Networks
生成对抗网络是生成模型的一个分类。生成模型在很多方面有应用。在这个向导中,这个模型指的是用某种方式去学习并表达针对一个训练数据集分布的估计,也就是$p_{data}$,然后学习描绘一个估计对于一些分布。结果是一个概率分布$p_{model}$。在一些例子中,模型明确的估计$p_{model}$,就像图一那样。在其他情况下,模型只可能从$p_{model}$中生成样本,如图2。一些模型可以两个都做。GANs主要关注在样本生成,尽管可以设计GANs都做两者。
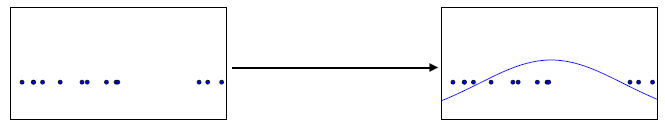
Figure1:有些生成模型通过密度估计。这些模型通过从未知的数据生成分布$p_{data}$来获取训练数据样本,然后得到此未知分布的估计。$p_{model}$估计可以给一个特殊的x值进行估计以获得对于真实密度$p_{model}(x)$的$p_{model}(x)$估计。这个图片展示了一个一维数据收集样本的过程,和一个高斯模型。
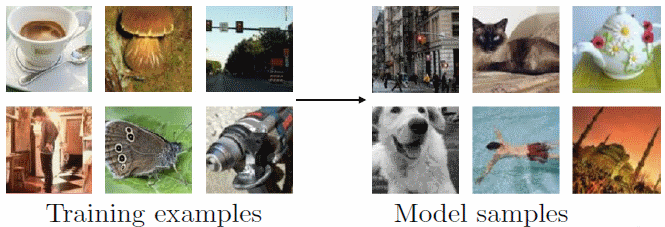
Figure2:一些生成模型可以从模型分布中生成样本。此图介绍的过程中,我们展示了ImageNet数据集中的样本。
为什么学习生成模型?
一个可能合理的解释对于这个问题,仅仅是因为生成模型可能比提供的密度函数估计有更好的表现。毕竟,当适用于图像时,模型只是尝试提供更多的图片,但是世界并不缺乏图片。
这里有一些学习生成模型的原因,包括:
- 从生成模型训练和采样是一个很好的测试对于我们的能力在表现和控制高纬度概率分布上。高纬度概率分布是一个重要的课题,在宽广的多样化的应用数学和工程领域。
- 生成模型可以在很多方面被应用到增强学习中(reinforcement learning)。增强学习算法可以分成两类;model-base和model-free,model-base算法包含一个生成模型。时间序列数据的生成模型可以被应用到模拟可能的未来。例如模型可以被应用到 计划(planning),和在多样化方面的增强学习。一个生成模型应用到 计划(planning) 可以通过未来世界的状态学习到一个条件分布,给定当前世界的状态和一个agent可能采取的假设行动座位输入。agent可以询问模型用不同的潜在行为,然后选择行动倾向于产生与自己期望状态一致的模型的预测行为。最近一个模型的例子,Finn et al(2016b),然后最近的一个例子应用于planning模型,Finn and Levine(2016)。另一方面生成模型可能应用于增强学习使他可以学习一个虚幻的环境,错误的行动不会对agent产生伤害。生成模型还可以用于引导探索保持足迹对于提前企图被观测的或不同的行动有多大的不同情况。生成模型,特别是GANs,还可以用于反向增强学习(inverse reinforcement learning)。关于增强学习的内容在5.6节会有更多的描述。
- 生成模型可以通过缺失数据训练,以及可以对缺失数据的输入提供预测。一个特别有趣的缺失数据的例子是半监督学习(semi-supervised learning),对于很多训练样本的标签是缺失的。流行的深度学习算法典型的需要特别多的标签样例去概括的很好。半监督学习是一个策略对于降低标签数量。学习算法可以通过学习很多未标记的样本来提高推广能力,未标定的数据更容易的获得。生成模型,特别是GANs,可以让半监督学习表现的更好。在5.4节将进行更详细的描述。
- 生成模型,特别是GANs,使机器学习可以用于多模(multi-modal) 输出问题。对于很多任务来说,一个输入可能对应多个正确的输出,每一个输出都是可以接受的。一些传统的训练机器学习模型的平均,像对期望输出和预测输出的均方差进行最小化的方法,不可能训练模型像产生多个不同正确答案那样。一个里理想情况的例子是,预测下一个 架构(fram) 在一个视频中,就像图3展示的那样。

Figure3:Lotter et al.(2015) 提供了一个精彩的展示对于多模数据建模。在这个例子中,一个模型被训练去预测一个视频序列的下一帧。这个视频描画了一个计算机底灰的一个可移动的3D人类头部模型。左侧图像展示了真实的下一帧图像,这个模型将理想的预测图片。中间的图片展示了利用 mean squared error(mse) 方法训练的在真实的下一帧和模型预测的下一帧之间的可能发生的情况。模型被强迫的去选择一个单独的回答对于下一帧看起来像什么。因为有很多可能的未来,相应的头部有轻微的不同位置,单一回答这个模型选择了对于很多明显不同的平均值。这就导致了耳朵消失,眼睛变得模糊。使用一个额外的GAN loss,在右侧的图像就有很多输出变得容易理解,每个都是清晰的和可以认出的真实的图片。
- 最后,很多任务本质上需要从一些分布上产生真实的生成数据。
这样的任务本质上需要生成优质的样本包括:
- 单图像超解析度(single image super-resolution):在这个任务中,目标是将低解析度图像合成为高解析度相等的图像。生成模型是必须的,因为这个任务需要模型加入更多信息到图片中比原始输入的图像。

Figure4:Ledig et al.(2016) 展示了非常好的单张超分辨率图片的结果,这组结果展示了从多模分布(multimodal distribution)使用生成模型训练的生成真实样本的获益结果。最左边的图片是原本的高分辨率图片。然后通过downsampled去制作一个低分辨率的图片,然后使用不同的方法去试图恢复高分辨率图片。 双三次插值(bicubic method) 是一个简单的插值方法,不需要使用全部训练数据的统计。SRResNet 是用mse训练的神经络。SRGAN 是基于GAN的神经网络,SRGAN性能提升是因为他可以理解多个正确的回答,而不是对多种正确答案做平均化处理,从而中得到一个最好的输出结果。
这里有很多可能的高分辨率图像对应与低分辨率的。这个模型应该选择一个图像,从概率分布中选择可能的图像。选择一个从可能图像的平局值的图像将产生太过模糊的结果。详情看图4。
- 艺术创作任务。两个最近的任务都展示了生成模型,特别是GAN,可以用于创建交互式的程序帮助用户创建真实的图片对应于粗糙的场景在用户的想象中。查看图片5和图片6。
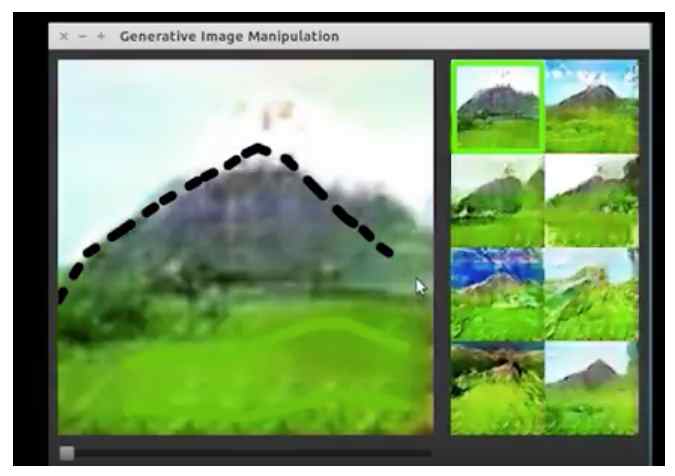
Figure5: Zhu et al.(2016) 开发了一个交互的程序称为 interactive generative adversarial networks(iGAN)。用户可以给一个图片画一个粗略的框架,然后iGAN使用GAN去产生最相似的真实图片。在这个示范中,一个用户乱画了一些绿色的线,iGAN生成了长满草的区域,用户画了一个黑色的三角形,iGAN生成了一个细致的山。艺术创作的应用是一个生成模型生成图像的原因。一个影片介绍了iGAN可以从下面的链接中查看: https://www.youtube.com/watch?v=9c4z6YsBGQ0
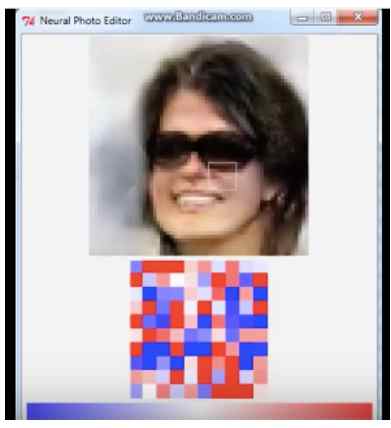
FIgure6:Brock et al(2016) 开发了内省对抗网络 introspective adversarial networks(IAN)。用户对图像做简单的修改,比如在一个区域中涂成黑色,从而希望加上黑色的头发,然后IAN可以将这种简单的涂抹转换为用户期望的照相写实主义的照片。应用允许用户在照片上创建真实的改动,这是学习生成模型创建图像的一个原因。
- Image-to-Image转换应用可以将航空图像转换为地图或将素描转换为图片。还有很长的路对于创建应用,很难预料但是可以被发现。详情看图7。
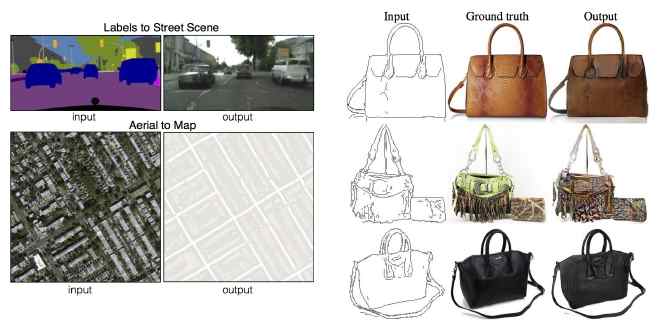
Figure7: Isola et al.(2016) 创建了一个叫做图像到图像转换的应用,包含很多图像种类的转换:将卫星图像转换为地图,将素描转换成照片写实主义的照片,等。因为很多这些转换有多个正确的输出对于每个输入,所以很重要的是使用生成模型去正确的训练模型。特别的,Isola et al(2016) 使用了GAN。图像到图像的转换提供了很多示例,一个创新的设计可以找到多种意料之外的应用对于生成模型。在未来,肯定很多创新应用会被发现。
所有这些以及其他生成模型的应用提供了足够多的理由去投入时间和资源到提高生成模型中。
生成模型是怎么工作的?GANs与其他模型有什么区别?
我们现在已经知道了生成模型可以做什么,以及值得去使用的原因。现在我们可以讨论:一个生成模型实际是如何工作的?特别的,GAN是如何工作的,以及与其他生成模型的区别?
最大似然估计(Maximum likelihood estimation)
为了简化讨论,我们将要集中在生成模型使用最大似然工作的方面上。不是每个生成模型都是用最大似然。一些生成模型默认不使用最大似然,但是可以是以哦那个。(GAN就是这一类)。通过忽略不使用最大似然的模型,集中在那些本来通常不使用最大似然的模型的最大似然版本,我们可以消除一些分散注意力的不同在不同模型之间。
最大似然估计的基本理念是用来估计概率模型参数$\theta$的一种方法,定义一个模型并提供一个概率分布估计。之后使用最大似然作为概率,模型分配给训练的数据:$\prod_{i=1}^{m}p_{model}(x^{(i)};\theta)$,一个数据集包含$m$去训练样本$x^{(i)}$。
简单来说,最大似然估计为模型选择了一个参数,最大化训练数据的可能性。在对数空间(log space)最容易到底此目的,我们计算一个算数和,而不是对每个样本进行处理。通过使用算术和使得对应模型的似然的导数的数学表达变得简单, 并且当在数字计算机上计算时, 其对数值问题不敏感, 比如说,当对几个很小的概率值进行相乘计算时会出现下溢(underflow)问题。
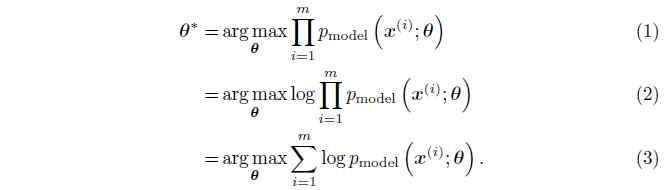
在方程2中,我们使用了以下特性:$\arg\max_{v}f(v)=\arg\max_{v}\log f(v)$,对于正数$v$,对数函数可以对所有范围的值进行最大化,却不改变最大化的区域。
最大似然的处理过程可以参考图8。
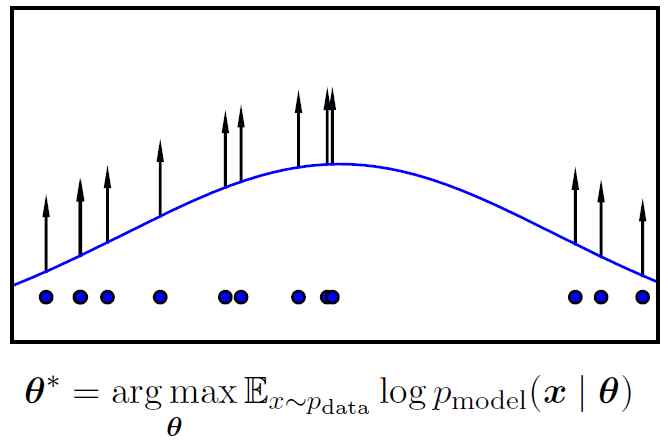
Figure8: 最大似然处理过程包括: 首先根据数据生成的分布来采样一些样本来构建训练数据集,然后通过提高模型在这些数据上概率值,来最大化此训练数据上的似然。这张图片展示了一个针对一维数据的高斯模型,我们可以看到不同的数据点会拉高密度函数的不同的部分。由于这个密度函数的总和必须是1,所以不可能将所有点都拉高到最大的概率;随着一个点被拉高将不可避免的使其他的地方被拉低。最终的密度函数是所有局部点的向上力的一个平衡。
我们也可以认为最大似然估计是最小化数据生成分布(data generating distriution)与模型分布的KL散度:
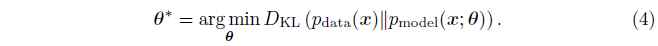
理想情况下,如果$p_{data}$是$p_{model}(x;\theta)$分布的一种分布, 那么模型就可以很好的覆盖$p_{data}$。在实际应用中,我们无法获取$p_{data}$本身,只能使用包含有$m$个样本的训练数据集。使用这$m$个样本可以定义一个经验性分布$\hat{p}{data}$来近似$p{data}$。最小化$\hat{p}{data}$$与$p{data}$的KL散度等价于在训练数据集上最大化对数似然(log-likelihood)。
关于更多的最大似然以及其他统计估计方法的内容, 请参考 Goodfellow et al. (2016) 的第五章。
深度生成模型的分类
如果我们限制注意力到使用最大似然的深度生成模型,那么我们可以通过计算他的似然和梯度,或对这些数值的近似计算的方式来比较几个模型。像我们前面提到的,很多模型经常使用最大似然以外的原理,为了降低这些模型之间的不同,我们可以检查这些模型的最大似然变量。根据这个方法,我们构建了图9展示的分类。树中的每个叶子都有自己的优点和缺点。GANs被设计成避免这些缺点的表现在以前存在的,但是也有很多新的缺点。
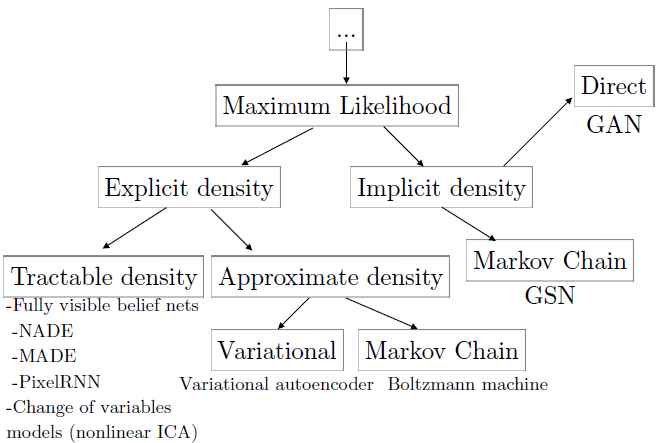
Figure9:深度生成模型可以通过最大似然的原理进行训练,不同方法的差异在于如何表达或近似似然。在分类树的左边分支,模型构建了一个显示的密度,$p_{model}(x;\theta)$,然后一个显式的似然可以被最大化。在这些显式密度模型中,密度可以被轻易的估计,或者是很难办的,这意味着最大化似然是必须的使用变分近似(variatioanl approximations)或Monte Carlo approximations(或者两者都是)。在树的右边分支,模型没有显式的表达一个数据空间的概率分布。取而代之的是,模型提供了一些方法来尽量少的直接的与概率分布接触。通常,概率模型的间接的平均的交互可以从中提取样本。一些这种隐式的模型使用了Markov Chain来提供从数据分布中提取样本的能力;这些模型定义了一种方法随机的转换一个存在的样本为了获得其他样本从相同的分布中。其他的方法可以从没有输入的情况下,通过一个简单的步骤生成样本。尽管使用了GAN的模型有时被用来定义显式的密度,GAN的训练算法只使用模型的能力去生成样本。GAN还使用最右边叶子的策略来进行训练:使用要给隐式的模型,模型直接从模型表达的分布中生成。
显式密度模型
图9的左边展示了模型定义了一个显式的密度函数$p_{model}$。对于这类模型,最大化似然是简单的;我们可以简单的将模型的密度函数的定义插入到似然的表达式中,然后使用梯度优化。
显式密度模型中的主要难点是设计一个模型,可以捕获所有复杂的数据去被生成当坚持可被处理的计算。这里有两个不同的步骤用于面对这个挑战:
- 仔细构建一个模型,保证结构的可处理性,像2.3.1节中说的那样。
- 使用那些对似然以及梯度容易进行近似处理的模型,在2.3.2节中有描述。
易处理的显式模型
在分类树最左边的分支中,是易于计算的定义了一个显式密度函数的模型。这个模型目前有两个流行的方法:完全可见置信网络(fully visible belief networks) 和 非线性独立成分分析(nonlinear independent components analysis)。
完全可见置信网络(Fully visible belief networks(FVBN))
FVBN(Frey et al,1996) 模型使用概率的链式规则来将一个$n$维向量$x$的概率分布分解为一个一维向量的概率分布:
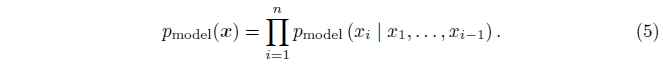
FVBN是三种生成模型中的一个流行的方法,与GAN和变分autoencoder。他们组成了DeepMind的复杂生成模型的基础,比如WaveNet(Ord et al.2016)。WaveNet可以生成逼真的人类的语音。FVBN的主要缺点是每一次计算智能生成一个词条:首先$x1$,然后$x2$,等,所以生成样本的复杂度为$O(n)$。最新的FVBN,比如WaveNet,每个$x_{i}$的分布都使用深度神经网络计算,所以每一个n步需要一个非凡的计算量。并且,这些步骤不可以并行。WaveNet计算1秒语音需要两分钟的计算时间,所以还不能被应用于交互谈话中。GAN被设计的可以生成所有$x$并行的,产生更好的生成速度。
非线性独立成分分析(Nonlinear independent components analysis)
另一种显式密度函数的深度生成模型是基于定义连续的,非线性转换的两个不同空间之间。例如,如果一个向量的潜在变量$z$和一个连续的,可谓的,可逆的转换矩阵$g$,$g(z)$生成一个样本从模型在$x$空间中,也就是:
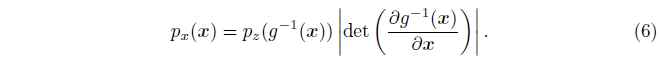
密度$p_{x}$是易处理的如果密度$p_{z}$是易处理的,然后决定性的Jacobian的$g^{-1}$是易处理的。换句话说,一个简单的关于$z$的分布包含一个转换的$g$,变形空间在复杂化的方式上可以生成一个复杂的分布$x$,如果$g$是小心设计的,那么这个密度也是易于处理的。使用非线性$g$函数的模型可以追溯到Deco and Brauer(1995)。这个分类中最新的成员是NVP(Dinh et al,2016)。图10展示了一些可视化的ImageNet样本通过NVP生成的。非线性ICA模型的主要缺点是他们利用限制的选择对于函数$g$。特别的,可逆的需求意味着潜在的变量$z$必须有相同的维度像$x$。GAN被设计去利用很少的需求在$g$上,以及特别的,允许$z$的维度高于$x$。

Figure10:使用Real NVP模型产生的样本,模型使用64x64的ImageNet图像训练。
关于更多的FVBN使用的基于链式规则的概率,以及关于非线性ICA模型中的确定性转换对概率密度的影响的更多内容请参考Goodfellow et al.(2016)的第三节。
总之,模型定义了一个显式的,易处理的密度是很有效的,因为他们允许使用最优化算法直接的在对数似然的训练数据上。
需要近似的显式模型
为了克服显式密度函数由于模型设计的需要带来的缺陷,出现了另外的一些模型,这类模型依旧提供显式密度函数,但是却不宜计算,需要使用近似的方式来最大化似然。这类方法可以分为两类:决定式近似,通常指变分方法(bariational methods),以及使用随机近似,通常有Markov chain Monte Carlo方法。